News Story
‘Priming’ helps the brain understand language even with poor-quality speech signals
When we listen to speech, our brains rapidly map the sounds we hear into representations of language, and use complex cognitive processes to figure out the intended meaning. Understanding how the brain transforms acoustic signals into meaningful content is a fundamental goal of the auditory neurophysiology field.
A large body of research has demonstrated that the brain responds to many different features present in speech signals, with reliable latencies and amplitudes for each occurrence of a feature. These features include acoustic aspects like the speech envelope (the time-varying instantaneous energy of the speech waveform) and the envelope’s onset (moments in time when the speech envelope is rapidly rising), as well as linguistic units such as word onsets, phoneme onsets and context-based measures along different levels of the linguistic hierarchy from speech sounds to linguistic unit, to—ultimately—language meaning.
The discovery and exploration of this “neural speech tracking” has advanced the understanding of how the brain rapidly maps an acoustic speech signal onto linguistic representations and ultimately meaning.
However, despite this progress, it’s still not clear how our understanding of what a speaker is saying (speech intelligibility) corresponds to our brain’s neural responses. Many studies addressing this brain signal processing question have tried techniques like varying the level of intelligibility by manipulating the acoustic waveform. Unfortunately, these efforts make it hard to cleanly disentangle the effects of changing the intelligibility from also changing the acoustics.
Now, University of Maryland research published in the journal Proceedings of the National Academy of Sciences of the United States of America (PNAS) offers a new way to approach the question. “Neural tracking measures of speech intelligibility: Manipulating intelligibility while keeping acoustics unchanged” was written by I. M. Dushyanthi Karunathilake (ECE Ph.D. 2023); alumnus Joshua P. Kulasingham (ECE Ph.D. 2021), a postdoctoral researcher at Linköping University, Linköping, Sweden; and Professor Jonathan Z. Simon (ECE/ISR/Biology), who advised both Karunathilake and Kulasingham.
The authors used brain data gathered from non-invasive magnetoencephalography (MEG) recordings to study neural measures of speech intelligibility and shed light on this connection. They knew that MEG responses during continuous speech listening time lock to acoustic, phonemic, lexical, and semantic stimulus features, and reasoned that these could provide an objective measure of when degraded speech is perceived as intelligible. This could yield new insight into how the brain turns speech into language.
Dushyanthi notes, “We’ve conducted many studies on these acoustic stimulus features, examining how they vary with selective attention and different noise levels. The other stimulus features have been studied in the context of continuous speech processing. However, specifically focusing on intelligibility using these stimulus features is completely new.”
About the research
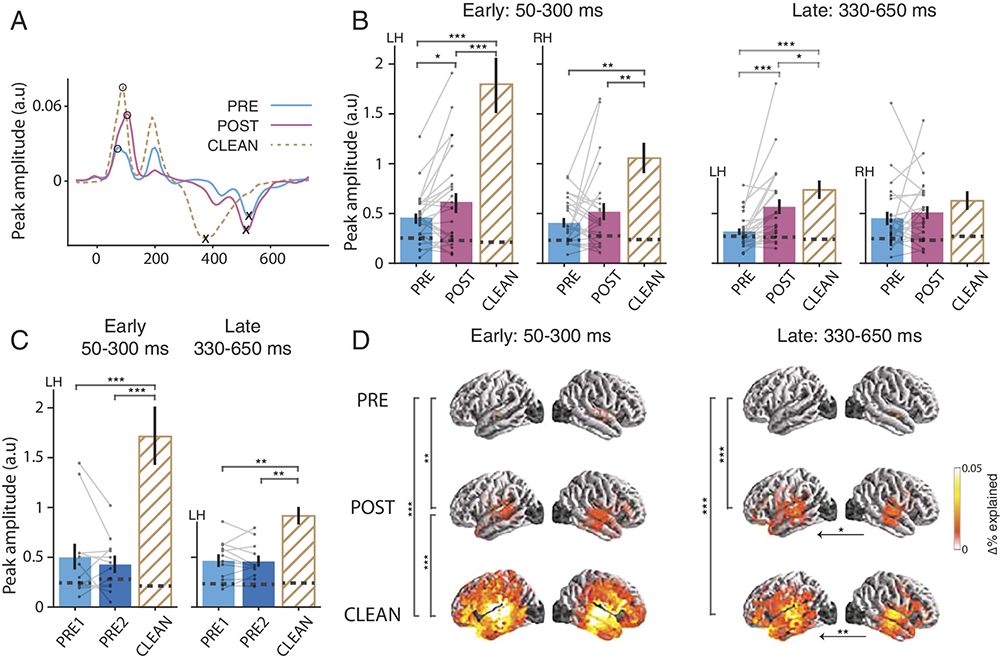
In the study, 25 young adults were twice presented with acoustically identical degraded speech stimuli; the second presentation was preceded by the original, nondegraded version of the speech, which "primes" the subject to better understand the degraded version. This “intermediate priming” was so strong it actually generated a “pop-out” percept, i.e., the subjects could understand much of the degraded speech without needing to exert any effort: the intelligibility of the second degraded speech passage was dramatically improved. It allowed the researchers to investigate how intelligibility and acoustical structure affect acoustic and linguistic neural representations using multivariate temporal response functions (TRFs).
Using this method allowed the scientists to manipulate intelligibility while keeping the acoustics strictly unchanged, a simple and useful experimental design that addressed issues in prior studies.
See for yourself!
Here is an explanation of the experimental design, and a demonstration of the "priming" effect. You can run the experiment for yourself by hitting the play button. You will hear, in succession, the degraded speech, followed by the "priming" clear speech example, and then a repeat of the degraded speech. The last example should be more comprehensible to you than the first version you heard---even though it is exactly the same. This is the priming effect of hearing the clear speech. Does it work for you?
What does this mean?
The authors found no significant differences for measures that were time-locked to stimulus acoustics. However, they did find significant differences for measures time-locked to where boundaries would have been if the sample had not been degraded. The effect was most prominent at the long-latency processing stage, indicating top-down influence, and was left-lateralized, indicating the brain was engaged in language processing.
The experimental results confirmed that perceived speech clarity is improved by priming. TRF analysis reveals that auditory neural representations are not affected by priming; only by the acoustics of the stimuli. The authors’ findings suggest that segmentation of sounds into words emerges with better speech intelligibility, and most strongly at the later word processing stage in the brain’s prefrontal cortex. This is in line with the engagement of top–down mechanisms associated with priming.
The results show that word representations may provide some objective measures of speech comprehension.
“In addition to seeing a large enhancement of the neural correlate of (now-perceived) word boundaries, additional enhancement was seen for the neural correlate of contextual word surprisal, a statistical measure of how unexpected a word is in the context of preceding words,” Simon notes. “This is not generated by the mere presence of words but depends on semantic/syntactic recognition of the correct word.”
Any neuromarker of intelligibility, defined as speech understanding despite acoustic degradation, must be more “language processing” than “acoustical processing,” says Simon. “The use of mTRFs allows us to distinguish both of these from acoustic processing.”
In addition, Simon notes, “The results coming from this research could be a treasure for clinical populations ill-suited for behavioral testing such as infants and individuals with cognitive disabilities. For instance, very young children understand speech and language much earlier than they can reliably report whether they understand it or not.”
Published December 7, 2023
Related Stories
Stories / September 26, 2023
New UMD Division of Research video highlights work of Simon,...

Stories / October 25, 2021
How does the brain turn heard sounds into comprehensible...
Stories / July 8, 2021
NIH grant furthers poststroke recovery research of Marsh, Simon

Stories / December 14, 2020
Emerging from the fog: Little understood post-stroke cognitive...

Stories / August 19, 2020
New algorithms for estimating the latent dynamics underlying...

Stories / September 23, 2019
AESoP symposium features speakers, organizers with UMD ties
Stories / April 28, 2023
Autism Research Resonates in Hearing-Focused Project

Stories / March 6, 2023
Isolated Cells, Inclusive Science
Stories / February 6, 2023
Discovering a digital biomarker for post-stroke cognitive...
Stories / October 26, 2022
Training Can Improve Older Adults’ Ability to Discriminate...
